
開発環境:Ubuntu 22.04(x86 64bit)
2つのテキストファイルに違いがあるかどうかを、素早く比較するツールを公開します。
本ツールは、Linux上で動作します。
テキストファイルの比較には、WinMerge、DF、Inquire等を利用する機会が多いと思います。
これらはGUIベースで視覚的にファイルの違いが確認できて便利です。
ただ、サイズの大きなファイルに違いがあると、結果を表示するまでに時間がかかります。
数十MBのファイルを比較すると、応答なしになることも。
当ツールは、2つのファイルに違いがあった時点で、差異を表示して処理を中断します。
その差異が許容できる場合には、比較しない範囲に指定して、またすぐに比較できます。
こういった感じで、比較したい範囲の内容が同じであるかを、素早く確認できます。
こんな時に使えます
・プログラム修正前後で、出力ファイルに差異がないことを確認(単体テスト)
・システム更改時に、出力ファイルを現新比較(結合テスト)
ツールの特徴
ツールの特徴は、以下の通りです。
- 2つのテキストファイルに違いがあるかどうかを、短時間で検出可能。
- 機能よりも速度を優先。2つのファイルに違いを検出した時点で、比較を中断します。
- 違いのある行番号と内容を表示。
- 固定長ファイル、可変長ファイルの両方に対応。
- 固定長の場合、比較しない桁を指定可能。
- 可変長の場合、比較しないフィールドを指定可能。
- ファイルをソートしてから比較可能。
ただしこの機能は、ファイルが大容量になると遅くなります。 - 1行の長さは4,096バイトまで。
当ツールが提供するコマンド
当ツールは、2つのコマンドを提供しています。
どちらかのコマンドをご使用ください。
① fdiff.sh …ファイルをソートしてから比較。
比較するファイルのデータの並びが異なる場合に利用します。
※ファイルをソートして比較するため、差異として出力される行番号は
実際のファイルとずれます。
② fdiff …ファイルをそのまま比較。処理が速い。
ファイルのデータの並びが合っている場合は、こちらがおススメ。
起動方法
2つのコマンドの起動オプションは同じです。
① fdiff.sh <起動オプション>
② fdiff <起動オプション>
<起動オプション>
ファイル1 ファイル2 [-c|f] [-d<区切り文字>] [-e<除外情報>]
-c:固定長ファイル
-f:可変長ファイル
-d:区切り文字を指定。可変長ファイルでのみ指定可能。デフォルトはタブ。
-e:比較対象としない範囲を指定。
固定長ファイル:-e<開始カラム>,<バイト数>,… ※最大5組
可変長ファイル:-e<フィールド番号>,… ※最大10個
起動例(可変長ファイル)
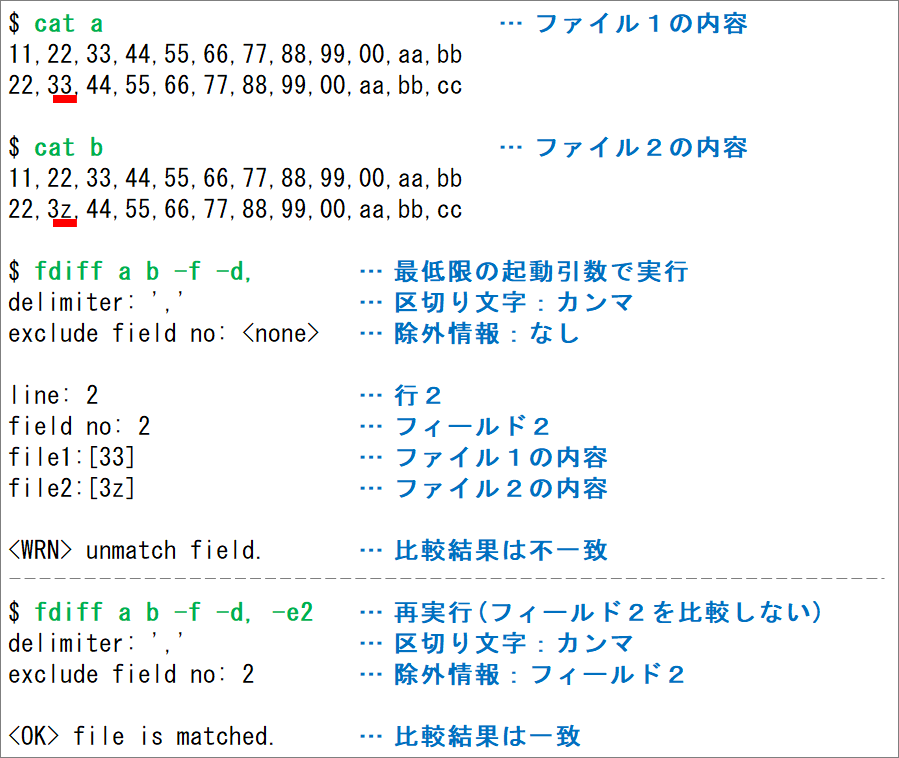
例1) 最低限の起動オプションで比較(区切り文字は、デフォルトでタブ)
fdiff ファイル1 ファイル2 -f
例2) 区切り文字を指定して、ファイルを比較(カンマ区切り)
fdiff ファイル1 ファイル2 -f -d,
例3)作成日を無視して比較
fdiff ファイル1 ファイル2 -f -d, -e5
※フィールド5(作成日)を比較しない
例4)作成日、更新日を無視して比較
fdiff ファイル1 ファイル2 -f -d, -e5,6
※フィールド5(作成日)、フィールド6(更新日)を比較しない
起動例(固定長ファイル)
例1) 最低限の起動オプションで比較
fdiff ファイル1 ファイル2 –c
例2)作成日を無視して比較
fdiff ファイル1 ファイル2 -c -e10,8
※10桁目から8バイト(作成日:YYYYMMDD)を比較しない
例4)作成日、更新日を無視して比較
fdiff ファイル1 ファイル2 -c -e10,8,20,8
※10桁目から8バイト(作成日)、20桁目から8バイト(更新日)を比較しない
使ってみる
- 比較するファイルが固定長/可変長のどちらであるかを確認してください。
可変長の場合は、この時に区切り文字も確認します(カンマ区切り、タブ区切り等)。
- 最低限の起動引数でツールを実行します。(前述の起動例を参照)
- 比較した結果が一致したら、ここまでで終了。
ファイルに差異がある場合は、無視してよい違いかどうか判断します。
- 無視してよい違いの場合、比較しない範囲を起動引数に指定して、再実行します。
- 上記3.~4.を繰り返します。
実行イメージ
可変長ファイル
固定長ファイル

終了ステータス
当ツールが返す終了ステータスは、下表のとおりです。
| 終了ステータス | 意味 |
| 0 | ファイル内容一致 |
| 81 | 行長不一致 |
| 82 | カラム内容不一致(固定長) |
| 83 | フィールド数不一致(可変長) |
| 84 | フィールド内容不一致(可変長) |
| 91 | 起動引数不正 |
| 92 | ファイルオープンに失敗 |
インストール方法
当ツールは、自由にご使用いただけます。
こちらの圧縮ファイルを、ダウンロードして下さい。

下記の要領で、ダウンロードしたファイルを、任意のディレクトリに解凍します。
tar zxf <ダウンロードファイル> 例)tar zxf fdiff_20230404.tar.gz
必要に応じて、解凍したディレクトリにパスを通してください。
例)PATH=$PATH:/home/test/fdiff
ソースコード
以下にソースコードを掲載します。
ダウンロードできない環境などで、ご使用ください。
fdiff.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
#include <unistd.h>
/* 終了ステータス */
#define RET_OK 0 /* 正常 */
#define RET_DFFR_LINE_CNT 81 /* 行長不一致 */
#define RET_DFFR_CLMN 82 /* カラム内容不一致 */
#define RET_DFFR_FLD_CNT 83 /* フィールド数不一致 */
#define RET_DFFR_FLD 84 /* フィールド内容不一致 */
#define RET_ARG_ERR 91 /* 引数不一致 */
#define RET_FILE_OPEN_ERR 92 /* ファイルOPEN失敗 */
/* 定数 */
#define SIZ_ARG_BFFR 128 /* パラメータサイズ */
#define SIZ_LN_BFFR 4096 /* 行バッファサイズ */
#define KIND_EXCLD_NONE 0 /* 除外種別:指定なし */
#define KIND_EXCLD_CLMN 1 /* 除外種別:カラム */
#define KIND_EXCLD_FLD 2 /* 除外種別:フィールド */
/* プロトタイプ宣言 */
void dspUsg();
int cmprClmn(int iLineCnt, char* chLineBuf1, char* chLineBuf2
, int iExcldCnt, int iaryExcld[]);
int cmprFld(int iLineCnt, char* chLineBuf1, char* chLineBuf2
, char* chDlmtr, int iExcldCnt, int iaryExcld[]);
int getFldCnt(char* lbuf, char* chDlmtr);
char* getFld(char* pchStr, char* chDlmtr, char* chOutBuf);
/*
* 関数名:fdiffメイン
* 処理:
* 1) 引数に指定された2つのファイルを比較する。
* 2) 比較結果を標準出力へ出力する。
* 引数:
* (i) char* : 比較対象ファイル1(必須)
* (i) char* : 比較対象ファイル2(必須)
* (i) char* : -c カラム比較
* (i) char* : -f フィールド比較(デフォルト)
* (i) char* : -d<区切り文字> (デフォルトはタブ)
* 区切り文字を1文字指定。
* このオプションは、フィールド比較で指定可能。
* (i) char* : -e<除外情報>,..
* ここで指定するカラム/フィールドは、比較されない。
* 差異を無視したい場合に指定する。
* カラム比較:開始桁とバイト数の組合せを指定(カンマ区切り)
* フィールド比較:フィールド番号を指定
* 複数の除外情報を指定する際は、半角カンマで繋げる。
* カラム比較 : -e10,8,20,8 → 10~17桁、20~27桁を無視
* フィールド比較: -e30,31 → フィールド30、31を無視
* 戻り値:
* 0 : 正常(ファイル内容一致)
* 8x : 警告(ファイル内容不一致)
* 9x : 異常
*/
int main(int argc, char *argv[]) {
FILE* fin1;
FILE* fin2;
char chArgBuf[SIZ_ARG_BFFR];
char chDlmtr[SIZ_ARG_BFFR];
char chExcldInf[SIZ_ARG_BFFR];
char chLineBuf1[SIZ_LN_BFFR];
char chLineBuf2[SIZ_LN_BFFR];
char* pchWk;
char* pchRet1;
char* pchRet2;
char* pchFName1;
char* pchFName2;
int iaryExcld[] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
int i;
int j;
int iRet;
int iOpt;
int iLineCnt;
int iExcldCnt;
int iExcldKind;
/*--------------*/
/* 引数チェック */
/*--------------*/
if (argc < 3) {
dspUsg();
return RET_ARG_ERR;
}
pchFName1 = argv[1];
pchFName2 = argv[2];
opterr = 0;
iExcldCnt = 0;
iExcldKind = KIND_EXCLD_NONE;
strcpy(chDlmtr, "");
strcpy(chExcldInf, "<none>");
while (-1 != (iOpt = getopt(argc, argv, "cd:fe:"))) {
switch (iOpt) {
case 'd':
if ('-' == *optarg
|| KIND_EXCLD_CLMN == iExcldKind) {
dspUsg();
return RET_ARG_ERR;
}
strcpy(chDlmtr, optarg);
break;
case 'c':
if (KIND_EXCLD_FLD == iExcldKind
|| '\0' != chDlmtr[0]) {
dspUsg();
return RET_ARG_ERR;
}
iExcldKind = KIND_EXCLD_CLMN;
break;
case 'e':
if ('-' == *optarg) {
dspUsg();
return RET_ARG_ERR;
}
strcpy(chExcldInf, optarg);
pchWk = chExcldInf;
iExcldCnt = getFldCnt(chExcldInf, ",");
if ((sizeof(iaryExcld) / sizeof(int)) < iExcldCnt) {
dspUsg();
return RET_ARG_ERR;
}
for (i = 0; i < iExcldCnt; i++) {
pchWk = getFld(pchWk, ",", chArgBuf);
for (j = 0; j < strlen(chArgBuf); j++) {
if (! isdigit(chArgBuf[j])) {
dspUsg();
return RET_ARG_ERR;
}
}
iaryExcld[i] = atoi(chArgBuf);
if (0 == iaryExcld[i]) {
dspUsg();
return RET_ARG_ERR;
}
}
break;
case 'f':
if (KIND_EXCLD_CLMN == iExcldKind) {
dspUsg();
return RET_ARG_ERR;
}
iExcldKind = KIND_EXCLD_FLD;
break;
default:
dspUsg();
return RET_ARG_ERR;
}
}
if (KIND_EXCLD_NONE == iExcldKind) {
iExcldKind = KIND_EXCLD_FLD;
}
if (KIND_EXCLD_FLD == iExcldKind && (strlen(chDlmtr) < 1)) {
strcpy(chDlmtr, "\t");
}
/*----------*/
/* コンペア */
/*----------*/
if (KIND_EXCLD_CLMN == iExcldKind) {
printf("exclude column: %s\n", chExcldInf);
} else {
printf("delimiter: '%s'\n", chDlmtr);
printf("exclude field no: %s\n", chExcldInf);
}
printf("\n");
/* ファイルOPEN */
fin1 = fopen(pchFName1, "r");
if (NULL == fin1) {
printf("<ERR> file1 open error.\n");
return RET_FILE_OPEN_ERR;
}
fin2 = fopen(pchFName2, "r");
if (NULL == fin2) {
printf("<ERR> file2 open error.\n");
return RET_FILE_OPEN_ERR;
}
iRet = RET_OK;
iLineCnt = 0;
while (1) {
/* FILE1,FILE2読込 */
pchRet1 = fgets(chLineBuf1, sizeof(chLineBuf1), fin1);
pchRet2 = fgets(chLineBuf2, sizeof(chLineBuf2), fin2);
iLineCnt++;
/* 比較OK */
if (NULL == pchRet1 && NULL == pchRet2) {
printf("<OK> file is matched.\n");
break;
}
/* FILE1の行数 < FILE2の行数 */
if (NULL == pchRet1) {
printf("line no: %d\n", iLineCnt);
printf("<WRN> file1 line count less than file2.\n");
iRet = RET_DFFR_LINE_CNT;
break;
}
/* FILE1の行数 > FILE2の行数 */
if (NULL == pchRet2) {
printf("line no: %d\n", iLineCnt);
printf("<WRN> file2 line count less than file1.\n");
iRet = RET_DFFR_LINE_CNT;
break;
}
/* 行一致なら次の行へ */
if (0 == strcmp(chLineBuf1, chLineBuf2)) {
continue;
}
/* 1行比較 */
if (KIND_EXCLD_CLMN == iExcldKind) {
iRet = cmprClmn(iLineCnt, chLineBuf1, chLineBuf2
, iExcldCnt, iaryExcld);
} else {
iRet = cmprFld(iLineCnt, chLineBuf1, chLineBuf2
, chDlmtr, iExcldCnt, iaryExcld);
}
if (RET_OK != iRet) {
break;
}
}
/* ファイルCLOSE */
fclose(fin1);
fclose(fin2);
return iRet;
}
/*
* 関数名:起動方法出力
* 処理:
* 1) 起動方法の説明を出力する。
* 2) 比較結果を標準出力へ出力する。
* 引数:
* なし
* 戻り値:
* なし
*/
void dspUsg() {
printf("Usage: fdiff file1 file2 [-c|f] [-d<delimiter>] [-e<exclude info>,..]\n");
printf(" -c\n");
printf(" compare columns.\n");
printf(" -f\n");
printf(" compare fields.(default)\n");
printf(" -d<delimiter>\n");
printf(" specify 1 character.\n");
printf(" default is tab('\\t').\n");
printf(" this option is ignore in column comparesions.\n");
printf(" -e<exclude info>,..\n");
printf(" specify exclude columns or fields.\n");
printf(" exclude columns: -e<start column>,<exclude byte>,..\n");
printf(" exclude fields : -e<field no>,..\n");
printf("\n");
printf(" ex.) fdiff file1 file2 -c -e10,8,20,8\n");
printf(" fdiff file1 file2 -f -d, -e30,31\n");
printf("\n");
return;
}
/*
* 関数名:文字列比較(カラム単位)
* 処理:
* 1) 文字列をカラム単位で比較する。
* 引数:
* (i) int iLineCnt : 行番号
* (i) char* chLineBuf1 : 文字列1
* (i) char* chLineBuf2 : 文字列2
* (I) int iExcldCnt : 除外カラム情報数
* (I) int iaryExcld[] : 除外カラム情報
* 戻り値:
* RET_OK : 一致
* RET_DFFR_CLMN : 不一致
* RET_ARG_ERR : 除外情報不正
*/
int cmprClmn(int iLineCnt, char* chLineBuf1, char* chLineBuf2
, int iExcldCnt, int iaryExcld[])
{
char chWkLine1[SIZ_LN_BFFR];
char chWkLine2[SIZ_LN_BFFR];
char chPstnStr[SIZ_LN_BFFR];
int i;
int j;
int iUnmtchClmn;
strcpy(chWkLine1, chLineBuf1);
strcpy(chWkLine2, chLineBuf2);
/* 除外フィールド妥当性チェック */
if (0 != (iExcldCnt % 2)) {
dspUsg();
printf("<ERR> invalid exclude info.\n");
return RET_ARG_ERR;
}
/* 除外カラムセット */
for (i = 0; i < iExcldCnt; i += 2) {
for (j = iaryExcld[i]; j < iaryExcld[i] + iaryExcld[i + 1]; j++) {
if (strlen(chWkLine1) < j
|| strlen(chWkLine2) < j) {
dspUsg();
printf("<ERR> invalid exclude info.\n");
return RET_ARG_ERR;
}
chWkLine1[j - 1] = '*';
chWkLine2[j - 1] = '*';
}
}
/* 行比較(一致なら次の行へ) */
if (0 == strcmp(chWkLine1, chWkLine2)) {
return RET_OK;
}
/* 不一致メッセージ出力 */
iUnmtchClmn = 0;
strcpy(chPstnStr, "");
for (i = 0; i < strlen(chWkLine1); i++) {
if (chWkLine1[i] == chWkLine2[i]) {
strcat(chPstnStr, " ");
} else {
strcat(chPstnStr, "v");
iUnmtchClmn = i + 1;
break;
}
}
printf("line: %d\n", iLineCnt);
printf("column: %d\n", iUnmtchClmn);
printf(" %s\n", chPstnStr);
printf("file1 [%s]\n", chWkLine1);
printf("file2 [%s]\n", chWkLine2);
printf("\n");
printf("<WRN> unmatch column.\n");
return RET_DFFR_CLMN;
}
/*
* 関数名:文字列比較(フィールド単位)
* 処理:
* 1) 文字列をフィールド単位で比較する。
* 引数:
* (i) int iLineCnt : 行番号
* (i) char* chLineBuf1 : 文字列1
* (i) char* chLineBuf2 : 文字列2
* (i) char* chDlmtr : 区切り文字
* (i) int iExcldCnt : 除外フィールド情報数
* (i) int iaryExcld[] : 除外フィールド情報
* 戻り値:
* RET_OK : 一致
* RET_DFFR_FLD_CNT : フィールド数不一致
* RET_DFFR_FLD : フィールド内容不一致
* RET_ARG_ERR : 除外情報不正
*/
int cmprFld(int iLineCnt, char* chLineBuf1, char* chLineBuf2
, char* chDlmtr, int iExcldCnt, int iaryExcld[])
{
char chFldBuf1[SIZ_LN_BFFR];
char chFldBuf2[SIZ_LN_BFFR];
char* pchLineBuf1;
char* pchLineBuf2;
int i;
int j;
int iFldCnt1;
int iFldCnt2;
int iExcldFlag;
/* フィールド数比較 */
iFldCnt1 = getFldCnt(chLineBuf1, chDlmtr);
iFldCnt2 = getFldCnt(chLineBuf2, chDlmtr);
if (iFldCnt1 != iFldCnt2) {
printf("line: %d\n", iLineCnt);
printf("file1 field count:[%d]\n", iFldCnt1);
printf("file2 field count:[%d]\n", iFldCnt2);
printf("\n");
printf("<WRN> unmatch field count.\n");
return RET_DFFR_FLD_CNT;
}
/* 除外フィールド妥当性チェック */
for (i = 0; i < iExcldCnt; i++) {
if (0 == iaryExcld[i]) {
break;
}
if (iFldCnt1 < iaryExcld[i]) {
dspUsg();
printf("<ERR> invalid exclude info.\n");
return RET_ARG_ERR;
}
}
/* フィールド比較 */
pchLineBuf1 = chLineBuf1;
pchLineBuf2 = chLineBuf2;
for (i = 0; i < iFldCnt1; i++) {
pchLineBuf1 = getFld(pchLineBuf1, chDlmtr, chFldBuf1);
pchLineBuf2 = getFld(pchLineBuf2, chDlmtr, chFldBuf2);
iExcldFlag = 0;
for (j =0; j < iExcldCnt; j++) {
if (0 == iaryExcld[j]) {
break;
}
if (iaryExcld[j] == (i + 1)) {
iExcldFlag = 1;
break;
}
}
if (1 == iExcldFlag) {
continue;
}
if (0 != strcmp(chFldBuf1, chFldBuf2)) {
printf("line: %d\n", iLineCnt);
printf("field no: %d\n", i + 1);
printf("file1:[%s]\n", chFldBuf1);
printf("file2:[%s]\n", chFldBuf2);
printf("\n");
printf("<WRN> unmatch field.\n");
return RET_DFFR_FLD;
}
}
return RET_OK;
}
/*
* 関数名:フィールド数取得
* 処理:
* 1) 文字列に含まれるフィールド数を取得する。
* 引数:
* (i) char* lbuf : 文字列
* (i) char* chDlmtr : 区切り文字
* 戻り値:
* フィールド数
*/
int getFldCnt(char* lbuf, char* chDlmtr)
{
char* pt;
char chBuf[SIZ_LN_BFFR];
int iFldCnt;
pt = lbuf;
iFldCnt = 0;
while (NULL != (pt = getFld(pt, chDlmtr, chBuf))) {
iFldCnt++;
}
return iFldCnt;
}
/*
* 関数名:フィールド内容取得
* 処理:
* 1) 文字列から区切り文字で区切ったフィールドを取得する。
* 引数:
* (i) char* pchStr : 文字列
* (i) char* chDlmtr : 区切り文字
* (o) char* chOutBuf : 取得したフィールド内容
* 戻り値:
* 次のフィールドへのポインタ
* 文字列の終端では、NULLを返却
*/
char* getFld(char* pchStr, char* chDlmtr, char* chOutBuf)
{
char* pchDlmPos;
int iDlmSz;
strcpy(chOutBuf, "");
if ('\0' == *pchStr) {
return NULL;
}
strcpy(chOutBuf, pchStr);
pchDlmPos = strstr(chOutBuf, chDlmtr);
iDlmSz = 0;
if (NULL != pchDlmPos) {
*pchDlmPos = '\0';
iDlmSz = 1;
}
return pchStr + strlen(chOutBuf) + iDlmSz;
}
fdiff.mk ※行2、行5は、先頭の半角スペースを、タブに置き換えてください。
all:
gcc -o fdiff fdiff.c
clean:
rm -f fdiff
fdiff.sh
#!/bin/bash
BASE_DIR=`dirname $0`
RET_SIGINT=98
tmp_file1="/tmp/tmp_fdiff01.$$"
tmp_file2="/tmp/tmp_fdiff02.$$"
function rm_tmp_file() {
rm -f "${tmp_file1}"
rm -f "${tmp_file2}"
return
}
trap 'rm_tmp_file; exit ${RET_SIGINT}' SIGINT
# sort file1
arg1="${1:-""}"
if [ $# -ge 1 ] ;then
if [ -f "$1" ] ;then
sort -o "${tmp_file1}" "$1"
arg1="${tmp_file1}"
fi
fi
# sort file2
arg2="${2:-""}"
if [ $# -ge 2 ] ;then
if [ -f "$2" ] ;then
sort -o "${tmp_file2}" "$2"
arg2="${tmp_file2}"
fi
fi
shift
shift
# execute fdiff
"${BASE_DIR}"/fdiff "${arg1}" "${arg2}" "$@"
ret=$?
rm_tmp_file
exit ${ret}
コメント